 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplatshot: 3D Face Avatar Generation from a Single Unconstrained Photo
May 31, 2026Reconstructing a photorealistic 3D face avatar from a single unconstrained photograph is challenging: feed-forward 3D Gaussian Splatting (3DGS) models degrade on out-of-distribution inputs, while pretrained diffusion models produce high-fidelity images but lack multi-view consistency. We observe that these paradigms are fundamentally complementary: explicit 3D representations guarantee geometric consistency, whereas 2D diffusion priors ensure photorealism. Building on this, we propose SplatShot, a training-free framework that couples these representations directly within the denoising process. Given a base 3DGS face model and a single reference image, we jointly denoise all target views using a per-step 3D feedback loop. At each timestep, we predict clean images from the noisy latents, refit the 3DGS to these multi-view predictions, and back-propagate the photometric discrepancy between the 3DGS re-renderings and 2D predictions into the noise estimate. This steers the sampling trajectory toward strictly 3D-coherent, identity-faithful outputs. Experiments on diverse in-the-wild images demonstrate that SplatShot produces 3D avatars with superior identity preservation, photorealism, and multi-view consistency.
Conformal Certification of Reasoning Trace Prefixes
May 28, 2026Language model reasoning traces are rarely all-or-nothing; they frequently contain valid intermediate steps before a critical error occurs. Existing uncertainty quantification methods typically certify final answers or entire responses, failing to provide statistical guarantees for the proportion of a sequential trace that can be safely retained. To address this, we introduce CROP (Conformal Reasoning Output Prefixes), a verifier-agnostic calibration procedure for clean-prefix certification. Given any step-level risk proxy, CROP selects a calibrated threshold and returns the longest contiguous prefix whose step risk proxies remain below it, routing the uncertified suffix for downstream review or repair. Assuming exchangeability, CROP rigorously controls the marginal probability that the returned prefix contains an annotated error. Across six process-labeled reasoning datasets, we demonstrate that standard step-level metrics such as AUROC do not fully capture prefix utility, suggesting verifiers should instead be evaluated by certified prefix length. Furthermore, CROP balances over- and under-withholding, improving downstream repair accuracy by preserving valid intermediate reasoning while discarding misleading suffixes. Ultimately, this work positions prefix certification as a rigorous, practical bridge between process supervision, abstention, and repair.
GeoViSTA: Geospatial Vision-Tabular Transformer for Multimodal Environment Representation
May 14, 2026Large-scale pretraining on Earth observation imagery has yielded powerful representations of the natural and built environment. However, most existing geospatial foundation models do not directly model the structured socioeconomic covariates typically stored in tabular form. This modality gap limits their ability to capture the complete total environment, which is critical for reasoning about complex environmental, social, and health-related outcomes. In this work, we propose GeoViSTA (Geospatial Vision-Tabular Transformer), a vision-tabular architecture that learns unified geospatial embeddings from co-registered gridded imagery and tabular data. GeoViSTA utilizes bilateral cross-attention to exchange spatial and semantic information across modalities, guided by a geography-aware attention mechanism that aligns continuous image patches with irregular census-tract tokens. We train GeoViSTA with a self-supervised joint masked-autoencoding objective, forcing it to recover missing image patches and tabular rows using local spatial context and cross-modal cues. Empirically, GeoViSTA's unified embeddings improve linear probing performance on high-impact downstream tasks, outperforming baselines in predicting disease-specific mortality and fire hazard frequency across held-out regions. These results demonstrate that jointly modeling the physical environment alongside structured socioeconomic context yields highly transferable representations for holistic geospatial inference.
Fast Amortized Fitting of Scientific Signals Across Time and Ensembles via Transferable Neural Fields
Apr 21, 2026Neural fields, also known as implicit neural representations (INRs), offer a powerful framework for modeling continuous geometry, but their effectiveness in high-dimensional scientific settings is limited by slow convergence and scaling challenges. In this study, we extend INR models to handle spatiotemporal and multivariate signals and show how INR features can be transferred across scientific signals to enable efficient and scalable representation across time and ensemble runs in an amortized fashion. Across controlled transformation regimes (e.g., geometric transformations and localized perturbations of synthetic fields) and high-fidelity scientific domains-including turbulent flows, fluid-material impact dynamics, and astrophysical systems-we show that transferable features improve not only signal fidelity but also the accuracy of derived geometric and physical quantities, including density gradients and vorticity. In particular, transferable features reduce iterations to reach target reconstruction quality by up to an order of magnitude, increase early-stage reconstruction quality by multiple dB (with gains exceeding 10 dB in some cases), and consistently improve gradient-based physical accuracy.
Generating Humanless Environment Walkthroughs from Egocentric Walking Tour Videos
Mar 30, 2026Egocentric "walking tour" videos provide a rich source of image data to develop rich and diverse visual models of environments around the world. However, the significant presence of humans in frames of these videos due to crowds and eye-level camera perspectives mitigates their usefulness in environment modeling applications. We focus on addressing this challenge by developing a generative algorithm that can realistically remove (i.e., inpaint) humans and their associated shadow effects from walking tour videos. Key to our approach is the construction of a rich semi-synthetic dataset of video clip pairs to train this generative model. Each pair in the dataset consists of an environment-only background clip, and a composite clip of walking humans with simulated shadows overlaid on the background. We randomly sourced both foreground and background components from real egocentric walking tour videos around the world to maintain visual diversity. We then used this dataset to fine-tune the state-of-the-art Casper video diffusion model for object and effects inpainting, and demonstrate that the resulting model performs far better than Casper both qualitatively and quantitatively at removing humans from walking tour clips with significant human presence and complex backgrounds. Finally, we show that the resulting generated clips can be used to build successful 3D/4D models of urban locations.
The Surprising Effectiveness of Noise Pretraining for Implicit Neural Representations
Mar 30, 2026The approximation and convergence properties of implicit neural representations (INRs) are known to be highly sensitive to parameter initialization strategies. While several data-driven initialization methods demonstrate significant improvements over standard random sampling, the reasons for their success -- specifically, whether they encode classical statistical signal priors or more complex features -- remain poorly understood. In this study, we explore this phenomenon through a series of experimental analyses leveraging noise pretraining. We pretrain INRs on diverse noise classes (e.g., Gaussian, Dead Leaves, Spectral) and measure their ability to both fit unseen signals and encode priors for an inverse imaging task (denoising). Our analyses on image and video data reveal a surprising finding: simply pretraining on unstructured noise (Uniform, Gaussian) dramatically improves signal fitting capacity compared to all other baselines. However, unstructured noise also yields poor deep image priors for denoising. In contrast, we also find that noise with the classic $1/|f^α|$ spectral structure of natural images achieves an excellent balance of signal fitting and inverse imaging capabilities, performing on par with the best data-driven initialization methods. This finding enables more efficient INR training in applications lacking sufficient prior domain-specific data. For more details, visit project page at https://kushalvyas.github.io/noisepretraining.html
EgoGroups: A Benchmark For Detecting Social Groups of People in the Wild
Mar 23, 2026Social group detection, or the identification of humans involved in reciprocal interpersonal interactions (e.g., family members, friends, and customers and merchants), is a crucial component of social intelligence needed for agents transacting in the world. The few existing benchmarks for social group detection are limited by low scene diversity and reliance on third-person camera sources (e.g., surveillance footage). Consequently, these benchmarks generally lack real-world evaluation on how groups form and evolve in diverse cultural contexts and unconstrained settings. To address this gap, we introduce EgoGroups, a first-person view dataset that captures social dynamics in cities around the world. EgoGroups spans 65 countries covering low, medium, and high-crowd settings under four weather/time-of-day conditions. We include dense human annotations for person and social groups, along with rich geographic and scene metadata. Using this dataset, we performed an extensive evaluation of state-of-the-art VLM/LLMs and supervised models on their group detection capabilities. We found several interesting findings, including VLMs and LLMs can outperform supervised baselines in a zero-shot setting, while crowd density and cultural regions clearly influence model performance.
Efficient Conformal Volumetry for Template-Based Segmentation
Feb 28, 2026Template-based segmentation, a widely used paradigm in medical imaging, propagates anatomical labels via deformable registration from a labeled atlas to a target image, and is often used to compute volumetric biomarkers for downstream decision-making. While conformal prediction (CP) provides finite-sample valid intervals for scalar metrics, existing segmentation-based uncertainty quantification (UQ) approaches either rely on learned model features, often unavailable in classic template-based pipelines, or treat the registration process as a black box, resulting in overly conservative intervals when applied directly in output space. We introduce ConVOLT, a CP framework that achieves efficient volumetric UQ by conditioning calibration on properties of the estimated deformation field from template-based segmentation. ConVOLT calibrates a learned volumetric scaling factor from deformation space features. We evaluate ConVOLT on template-based segmentation tasks involving global, regional, and label volumetry across multiple datasets and registration methods. ConVOLT achieves target coverage while producing substantially tighter intervals than output-space conformal baselines. Our work paves way to exploit the registration process for efficient UQ in medical imaging pipelines.
COMPASS: Robust Feature Conformal Prediction for Medical Segmentation Metrics
Sep 26, 2025In clinical applications, the utility of segmentation models is often based on the accuracy of derived downstream metrics such as organ size, rather than by the pixel-level accuracy of the segmentation masks themselves. Thus, uncertainty quantification for such metrics is crucial for decision-making. Conformal prediction (CP) is a popular framework to derive such principled uncertainty guarantees, but applying CP naively to the final scalar metric is inefficient because it treats the complex, non-linear segmentation-to-metric pipeline as a black box. We introduce COMPASS, a practical framework that generates efficient, metric-based CP intervals for image segmentation models by leveraging the inductive biases of their underlying deep neural networks. COMPASS performs calibration directly in the model's representation space by perturbing intermediate features along low-dimensional subspaces maximally sensitive to the target metric. We prove that COMPASS achieves valid marginal coverage under exchangeability and nestedness assumptions. Empirically, we demonstrate that COMPASS produces significantly tighter intervals than traditional CP baselines on four medical image segmentation tasks for area estimation of skin lesions and anatomical structures. Furthermore, we show that leveraging learned internal features to estimate importance weights allows COMPASS to also recover target coverage under covariate shifts. COMPASS paves the way for practical, metric-based uncertainty quantification for medical image segmentation.
GIQ: Benchmarking 3D Geometric Reasoning of Vision Foundation Models with Simulated and Real Polyhedra
Jun 11, 2025
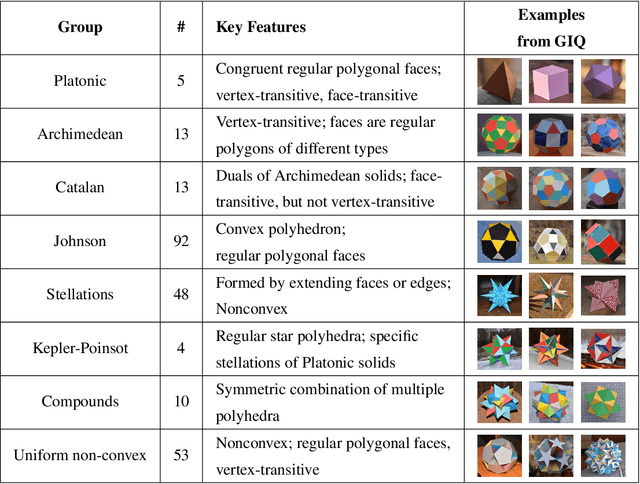
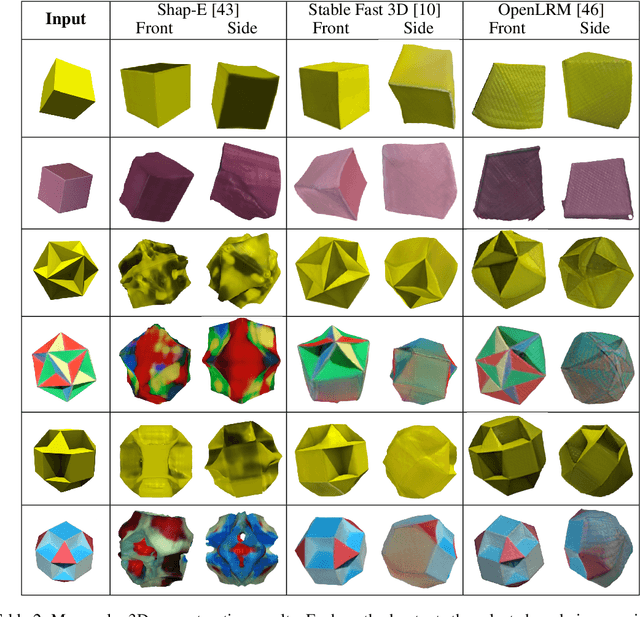
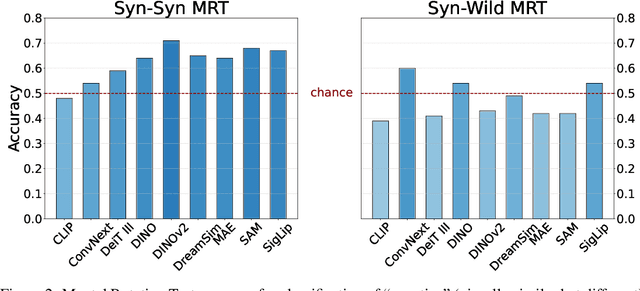
Monocular 3D reconstruction methods and vision-language models (VLMs) demonstrate impressive results on standard benchmarks, yet their true understanding of geometric properties remains unclear. We introduce GIQ , a comprehensive benchmark specifically designed to evaluate the geometric reasoning capabilities of vision and vision-language foundation models. GIQ comprises synthetic and real-world images of 224 diverse polyhedra - including Platonic, Archimedean, Johnson, and Catalan solids, as well as stellations and compound shapes - covering varying levels of complexity and symmetry. Through systematic experiments involving monocular 3D reconstruction, 3D symmetry detection, mental rotation tests, and zero-shot shape classification tasks, we reveal significant shortcomings in current models. State-of-the-art reconstruction algorithms trained on extensive 3D datasets struggle to reconstruct even basic geometric forms accurately. While foundation models effectively detect specific 3D symmetry elements via linear probing, they falter significantly in tasks requiring detailed geometric differentiation, such as mental rotation. Moreover, advanced vision-language assistants exhibit remarkably low accuracy on complex polyhedra, systematically misinterpreting basic properties like face geometry, convexity, and compound structures. GIQ is publicly available, providing a structured platform to highlight and address critical gaps in geometric intelligence, facilitating future progress in robust, geometry-aware representation learning.